This is the first of a two-part series that supplements the article Crypto Trading Bot -- Is It For Me?. Configurations of the crypto exchange need to compliment that of the trading bot for them to be able to communicate and trades could then be made.
As mentioned in the article, Binance is my crypto exchange of choice since it has the lowest trading fees, set at 0.1%. Binance developed its own crypto coin which they call Binance Coin (or BNB). Among other things, the primary purposes of this crypto is to pay for trading fees. When used, the trading fee gets a 50% discount, making it 0.05%.
First, register at Binance (if you don't have an account). (I'm requesting to be your referrer, with ID 26356236. Please use this code when asked for a referrer ID.)
Open your inbox and verify the email address you used to register with Binance. The next and most important part of the configuration is to use Binance coin to pay for trading fees. You will find this in your account settings, as seen below.
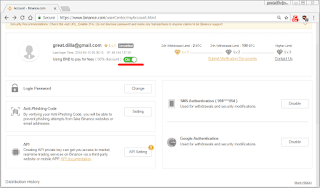
On the same page, you can generate API keys that the trading bot will use to access your Binance crypto exchange account (see lower left of the screenshot above). Click on the box "API setting".

Binance will be sending an email to confirm the API key creation. Again, check your inbox for that mail.
Once keys are created, make sure the "secret key" is noted down. It will not be shown again.
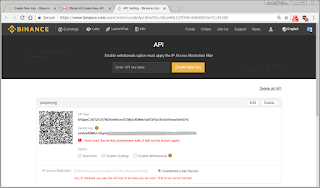
Last but definitely not least, enable enhanced security settings for your account. Enable 2FA (or two-factor authentication), either by SMS and/or Google Authenticator.
RELATED: Crypto Trading Bot -- Is It For Me?
You are now ready with your Binance crypto exchange account. Next, the cryptohopper settings.
References (affiliate links):
Binance Exchange.
CryptoHopper Bot.
As mentioned in the article, Binance is my crypto exchange of choice since it has the lowest trading fees, set at 0.1%. Binance developed its own crypto coin which they call Binance Coin (or BNB). Among other things, the primary purposes of this crypto is to pay for trading fees. When used, the trading fee gets a 50% discount, making it 0.05%.
First, register at Binance (if you don't have an account). (I'm requesting to be your referrer, with ID 26356236. Please use this code when asked for a referrer ID.)
Open your inbox and verify the email address you used to register with Binance. The next and most important part of the configuration is to use Binance coin to pay for trading fees. You will find this in your account settings, as seen below.

On the same page, you can generate API keys that the trading bot will use to access your Binance crypto exchange account (see lower left of the screenshot above). Click on the box "API setting".

Binance will be sending an email to confirm the API key creation. Again, check your inbox for that mail.
Once keys are created, make sure the "secret key" is noted down. It will not be shown again.

Last but definitely not least, enable enhanced security settings for your account. Enable 2FA (or two-factor authentication), either by SMS and/or Google Authenticator.
RELATED: Crypto Trading Bot -- Is It For Me?
You are now ready with your Binance crypto exchange account. Next, the cryptohopper settings.
References (affiliate links):
Binance Exchange.
CryptoHopper Bot.